
The Economist 基于 OpenAI 披露的数据,绘制了一张图,展示了不同的大模型及应用在算力需求上的变化。
纵轴是 OpenAI 用于描述 AI 计算量的算力单位 petaflop/s-days (每天执行 one petaflop per second)。OpenAI 定义一次乘法或一次加法为一个操作。如果每秒钟可以进行 10 的 15 次方运算,也就是1 peta flops,那么一天就可以进行约 10 的 20 次方运算,这个算力消耗被称为 1 个 petaflop/s-day。
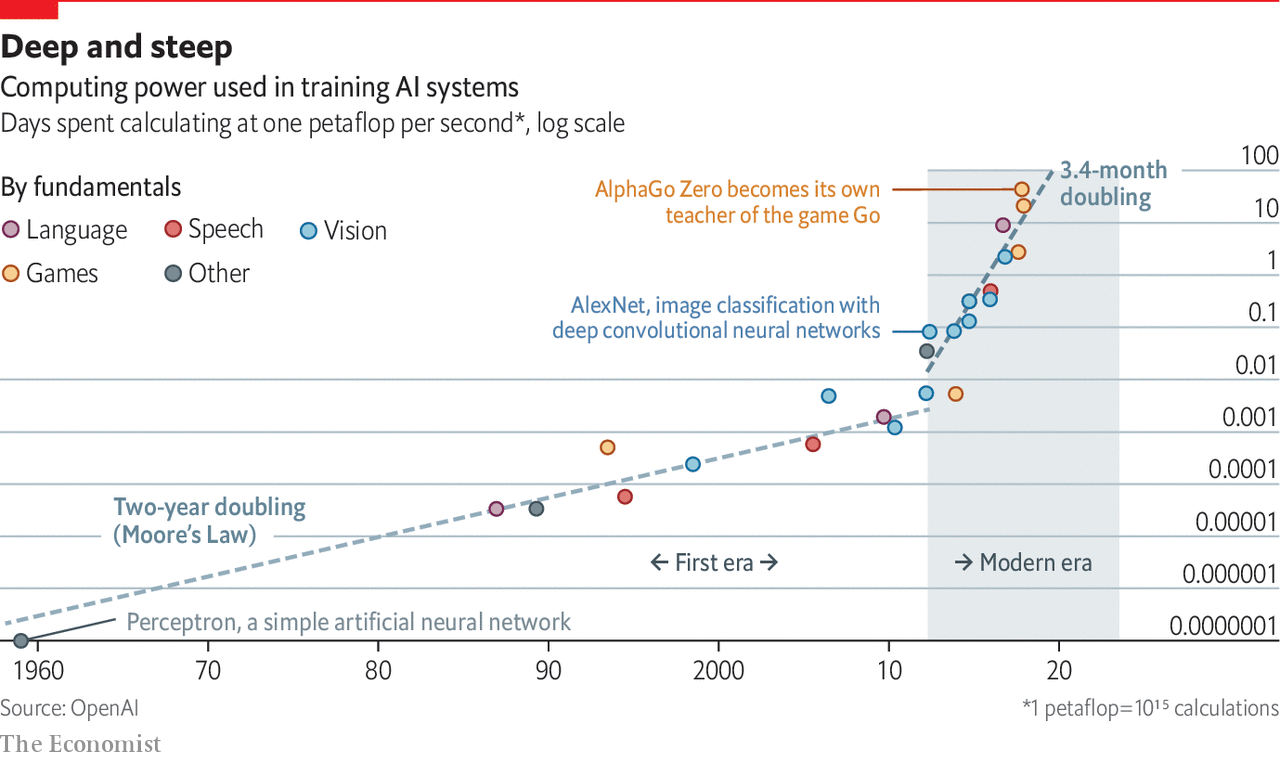
从整体看上,摩尔定律时代大约两年算力翻一番;而当前用于 AI 大模型训练的算力需求大约每 3.4 个月算力翻一番。
信通院的研究显示,2021 年北上广及周边省份地区算力规模指数较高,各地区不平衡仍然是很大的。其中北京、广东、上海位居前三,江苏、浙江、河北、山东紧随其后。
从这张图也可以反映 “东数西算” 西部枢纽面临的战略性机遇。
大模型 LLM 是生成式 AI 的技术核心。那就目前而言,企业在应用生成式 AI 时,会部署或引用多少个大模型呢?
Menlo Venture 针对北美和欧洲的企业调研显示,几乎所有的调研对象,无论组织大小,都会使用多个大模型。
越大的企业会同时使用多个大模型。这组调研数据,一定程度也反映了生成式 AI 在企业侧的格局还处于初期状态,格局还未形成。
格局未形成,如果大趋势又成立的话,这就意味着机会窗口。
对于生成式 AI 应用而言,训练数据的重要性是显而易见的。
通过对大量数据的积累和分析,开发者可以训练出更加精准和高效的模型,从而提升应用的性能和用户体验。数据飞轮闭环则是指通过用户使用应用产生的数据,进一步优化和迭代模型,形成一个持续循环的过程。
从易观和 CSDN 针对中国 AI 应用开发者的调研看,“领域数据量及数据获取难度使用成本” 是响 AI 应用开发者路径规划时最大的考虑因素。

